PCA,即主元分析法,是用来做数据降维的一种方法。从思想上讲,一个高纬的数据,往往包含很多多余的信息,我们希望将其取出,尽可能地降到一个较低的维度,但同时又必须保证其数据失真尽可能小。PCA就是一套算法,在保证重建误差最小的情况下,提取出高维数据的主元,从而实现数据的降维。
下面具体来说PCA算法在人脸识别中的算法流程,前提:有一个训练图集,里面放着同一个人的脸(对齐过的),并且每张图长宽的像素点都相同(比如160*120);有一个测试图集,里面放着待测图像,待测图像的长宽像素点与训练图集一样。
PCA的算法流程是:
一、训练流程
S1:构筑训练图像矩阵:将每一张人脸图张开成一维行向量(也可以是列向量,但以下的计算都是用行向量),训练集中所有图像组成一个训练图像矩阵,每一个行向量代表一张图。
S2:计算平均脸、协方差矩阵:平均脸就是将所有的行向量求平均得到的一个平均的行向量,将每张脸向量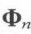 按下面公式计算得到协方差矩阵。
按下面公式计算得到协方差矩阵。
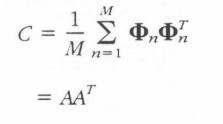
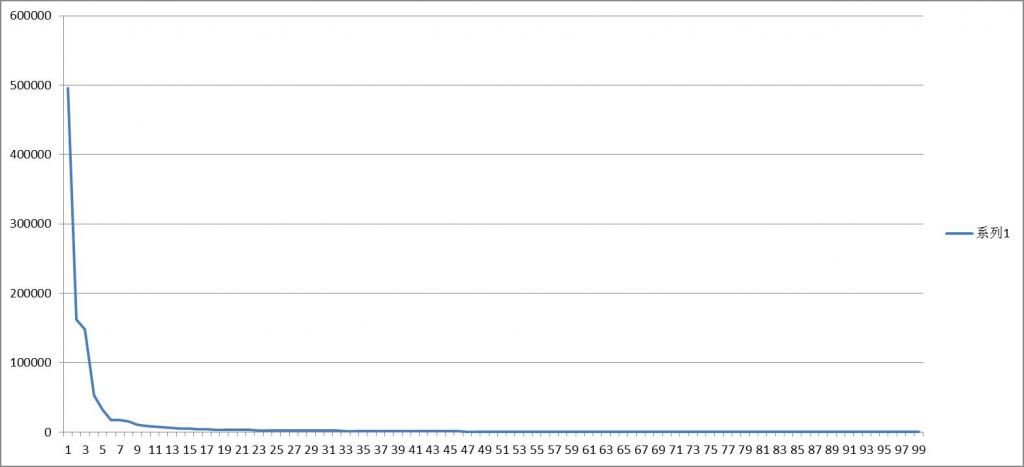
S3:计算协方差矩阵的特征值与特征向量,取前r大的特征值对应的特征向量构成r维特征空间,r<min(训练图集中图张数,每张图的像素点数)。为了使得r维特征空间更加具有代表性且更加的小,我们应该考虑特征值的变化情况,取更大的特征值,比如下面这种情况,我们取r=10即可以。
S4:按照下面公式将训练图集矩阵的每个行向量向特征空间投影,为每一张图得到投影后的r维向量,这就是降维后的每张图的特征向量了。

二、识别流程:
S1:保留训练流程中的平均脸与特征空间。
S2:构筑测试图像矩阵,与训练流程中的一样。
S3:将测试图像矩阵中的每一行按照训练流程s4中的公式向特征空间投影,得到每张图像矩阵的特征向量。
S4:根据投影后的特征向量与特征空间重建图像,计算原图像与重建后的图像间的距离。
S5:判断是否是人脸:设定阈值,如果原图像与重建后的图像间的距离小于阈值,则判断为人脸,继续s6,否则判否,识别结束。
S6:识别是否是特定人:设定阈值,并计算测试图像特征向量与所有训练图像特征向量间的欧氏距离,取最小的距离,如果最小距离小于阈值,则识别接受,否者就拒绝接受。
正如题目所示,这篇文章只是概述性的小结,说的很简单,以功能与算法流程为主,很多原理与细节没有展开,要想深入了解的,可以参考下面的文献:
关于PCA算法原理理解的:
《Eigenfaces for Recognition》——本文的公式都来自本论文,并没有仔细标明,具体参考这篇论文。
《基于PCA针对表情变化的人脸识别技术研究》
http://leen2010.blogbus.com/logs/124631640.html
用OPENCV编程实现PCA算法的:
http://apps.hi.baidu.com/share/detail/34585074
附:
OPENCV中的PCA使用(转)
|
对于PCA,一直都是有个概念,没有实际使用过,今天终于实际使用了一把,发现PCA还是挺神奇的。
在OPENCV中使用PCA非常简单,只要几条语句就可以了。
1、初始化数据
//每一行表示一个样本
CvMat* pData = cvCreateMat( 总的样本数, 每个样本的维数, CV_32FC1 );
CvMat* pMean = cvCreateMat(1, 样本的维数, CV_32FC1);
//pEigVals中的每个数表示一个特征值
CvMat* pEigVals = cvCreateMat(1, min(总的样本数,样本的维数), CV_32FC1);
//每一行表示一个特征向量
CvMat* pEigVecs = cvCreateMat( min(总的样本数,样本的维数), 样本的维数, CV_32FC1);
2、PCA处理,计算出平均向量pMean,特征值pEigVals和特征向量pEigVecs
cvCalcPCA( pData, pMean, pEigVals, pEigVecs, CV_PCA_DATA_AS_ROW );
3、选出前P个特征向量(主成份),然后投影,结果保存在pResult中,pResult中包含了P个系数
CvMat* pResult = cvCreateMat( 总的样本数, PCA变换后的样本维数(即主成份的数目), CV_32FC1 );
cvProjectPCA( pData, pMean, pEigVecs, pResult );
4、 重构,结果保存在pRecon中
CvMat* pRecon = cvCreateMat( 总的样本数, 每个样本的维数, CV_32FC1 );
cvBackProjectPCA( pResult, pMean, pEigVecs, pRecon );
5、重构误差的计算
计算pRecon和pData的"差"就可以了.
使用时如果是想用PCA判断“是非”问题,则可以先用正样本计算主成分,判断时,对需要判断得数据进行投影,然后重构,计算重构出的数据与原数据的差异,如果差异在给定范围内,可以认为“是”。
如果相用PCA进行分类,例如对数字进行分类,则先用所有数据(0-9的所有样本)计算主成分,然后对每一类数据进行投影,计算投影的系数,可简单得求平均。即对每一类求出平均系数。分类时,将需要分类得数据进行投影,得到系数,与先前计算出得每一类得平均系数进行比较,可判为最接近得一类。当然这只是最简单得使用方法
|
分享到:




相关推荐
PCA主元分析法 做故障诊断程序 基于数据驱动的 也可以做图像处理
经典主元分析(pca)方法的人脸识别源码,matlab编写
基于PCA的人脸识别m文件,可以运行,准确率还可以
基于PCA的人脸识别,有原理介绍,简单易懂,还有程序
利用PCA进行对ORL人脸库进行人脸识别的程序
资源名:matlab基于PCA+SVM的人脸识别系统_PCA_SVM_人脸识别_matlab 资源类型:matlab项目全套源码 源码说明: 全部项目源码都是经过测试校正后百分百成功运行的,如果您下载后不能运行可联系我进行指导或者更换。 ...
PCA人脸识别_人脸识别_OPENCV_C++
采用主元分析法 (PCA)进行 人脸 识别的 经典 方法之一 。本文利用 Matlab在 ORL人脸库上 实现 PCA初步人脸识别, 包括图像特征提取、人脸重构与识别方法设计。 讨论了用 奇异值 分解 等方法简化特征向量求解 ,并...
(2)了解PCA在人脸识别与重建方面的应用; (3)认识数据降维操作在数据处理中的重要作用; (4)学习使用MATLAB软件实现PCA算法,进行人脸识别,加深其在数字图像处理中解决该类问题的应用流程。
有全套代码,可以运行 主成分分析(PCA)是人脸识别中特征提取的主要方法,支持向量机(SVM)具有适合处理小样本、非线性和高维数问题,利用核函数且泛化能力强等多方面的优点
PCA 算法实现人脸识别 PCA 算法实现人脸识别 PCA 算法实现人脸识别 PCA 算法实现人脸识别
【人脸识别】基于PCA+LDA实现人脸识别matlab 源码.md
本matlab程序实现了基于PCA的人脸识别,并提供了相应的论文和测试数据集,并给出了测试结果。
数字图像与机器视觉中的经典案例,PCA+SVM的人脸识别系统,全套代码,可以直接运行
基于PCA和ICA的人脸识别,对于ICA算法有很好的步骤说明,还不错
基于PCA的人脸识别算法实现,用于人脸识别的学习
主元分析PCA理论分析及应用,
人脸识别
基于PCA的人脸识别系统,参照已有的 MATLAB 代码用 python 重写,使用numpy、matplotlib、tkinter库。
PCA算法可在MATLAB中配合人脸数据库实现人脸识别